Durante il ciclo di vita dello sviluppo del software possono andare storte diverse cose, come problemi tecnici, attacchi informatici e interruzioni del sistema. È inevitabile che si verifichino guasti imprevisti, che possono interrompere l'intero processo, limitare i risultati attesi e sprecare risorse vitali.
L'ingegneria del caos è una disciplina che studia come possono verificarsi questi guasti e fornisce metodologie per evitarli. Comprendendo la causa principale degli errori, gli ingegneri del caos possono sviluppare piani per prevenirli o mitigarli.
Quindi possiamo definire che l'ingegneria del caos è la pratica di iniettare intenzionalmente guasti in un sistema per testare la resilienza. L'obiettivo è identificare potenziali punti di guasto e correggerli prima che causino un'interruzione effettiva o altre interruzioni.
Ci sono molti modi per creare il caos in un sistema, ma la cosa più importante è avere un piano. Senza un piano, è facile creare più problemi di quanti ne risolvi. Quando crei il tuo piano, dovrai decidere cosa vuoi testare e come lo farai.
Più è complesso il sistema più è facile che un qualsiasi errore possa diventare grave. Il Chaos Engineering, “rompendo” e “provocando problemi” volontariamente, si integra con processi di Site Reliability Engineering(SRE) e di analisi applicativa per preparare i tuoi software ai fallimenti e quindi costruire i tuoi software in maniera resiliente.
Diverse aziende note come Netflix, Amazon, Google, ecc. hanno adottato questa disciplina per prevenire in modo proattivo interruzioni
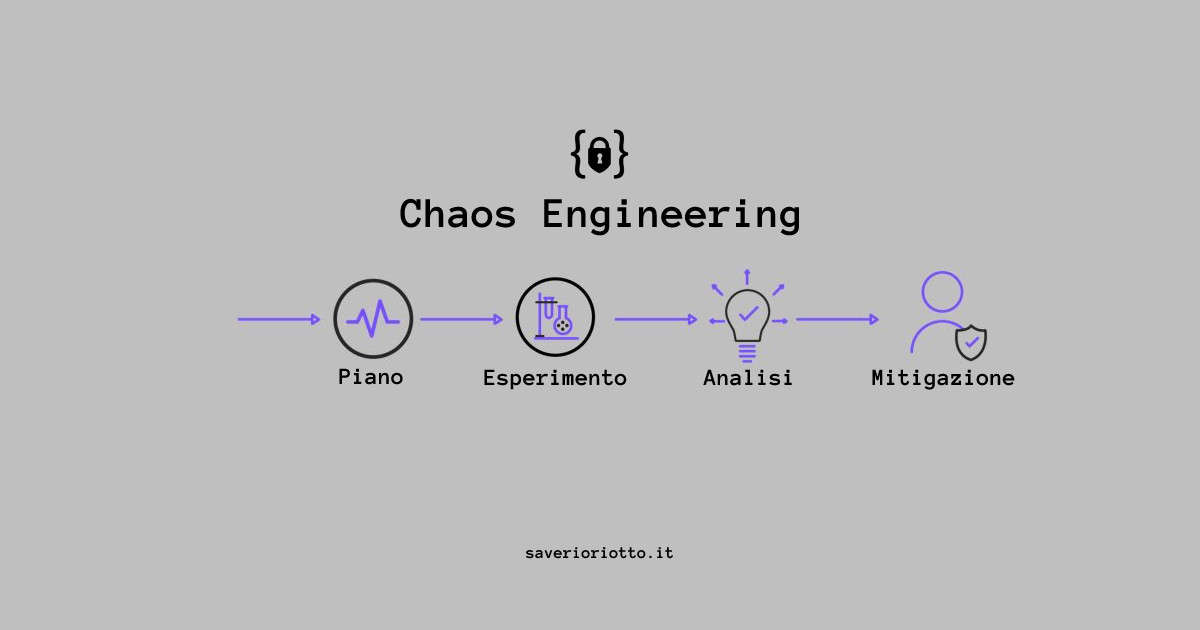
I principi dell'ingegneria del caos sono:
Piano: decidi cosa vuoi testare e come lo farai. L'obiettivo adesso è ipotizzare quali problemi possono incidere nel sistema. Cosa potrebbe andare storto in un sistema? Quali sono alcune potenziali vulnerabilità che possono essere sfruttate?
Esperimento: iniettare guasti nel sistema e vedere come reagisce. L'iniezione di errori è semplicemente il processo di introduzione di un problema in un sistema esistente per esporre una vulnerabilità. È essenzialmente l'abitudine di "lanciare una chiave inglese" in un sistema apposta per vedere cosa succede.
Analisi: utilizza i dati dei tuoi esperimenti per identificare potenziali punti di errore.
Mitigazione: se trovi un problema, puoi terminare l'esperimento per concentrarti sulla mitigazione. Altrimenti, puoi ridimensionare il tuo esperimento fino a quando non arrivi al nocciolo del problema.
Il rischio deve essere sempre gestito per le applicazioni soprattutto se sono critiche per il tuo business. Utilizzare il Chaos Engineering ti serve perchè:
- puoi determinare il rischio ed il costo ed impostare gli elementi come Service Level Indicators(SLI), Service Level Objectives(SLO) e Service Level Agreements(SLA);
- puoi testare i tuoi sistemi effettivamente in maniera completa senza lasciare nulla da parte;
- puoi emergere le proprietà e le componenti che magari sono più nascoste e che possono portare gravi problemi;
- puoi comprendere come adottare i piani di contingenza e di Business Continuity;
- puoi comprendere gli eventuali errori umani in produzione che normalmente non si riesce ad individuare durante i classici test come gli Unit Test e gli End-to-End.
In pratica grazie al Chaos Engineering riesci ad avere software, architetture, applicazioni pronte per qualsiasi grave problema. Se hai già provato un grave problema comprendi ancora di più perchè sarebbe stato ideale implementare il Chaos Engineering.
In definitiva, l'ingegneria del caos è l'impulso di qualsiasi progetto software di successo. Gli sviluppatori di software possono implementare l'ingegneria del caos per realizzare progetti che resisteranno alla prova del tempo.
Poiché i sistemi Web sono diventati molto più complessi con l'aumento dei sistemi distribuiti e dei microservizi, è diventato difficile prevedere i guasti del sistema. Quindi, per evitare che si verifichino fallimenti, dobbiamo tutti essere proattivi nei nostri sforzi per imparare dai fallimenti.

Programmatore informatico italiano, mi occupo di sviluppo sia Front-end che Back-end presso una grande azienda. La programmazione è stata la mia passione, insieme allo sport e al teatro che pratico tutt'ora. Ho deciso di aprire questo blog per dare consigli e condividerli con chi, come me, porta con sé questa passione. [..]




